Factor Analysis and Probabilistic PCA (PPCA)
Summary
Factor analysis (FA) is a probabilistic model for identifying low-rank structure in multivariate data via latent variables. It is a linear Gaussian model: observed data are modelled as a noisy linear transformation of latent factors . Probabilistic PCA (PPCA) is a special case with isotropic noise. Naive implementations suffer from non-identifiability; the constrained parametrisation (lower-triangular ) and amortized inference (marginalizing ) are the two key remedies.
Model Formulation
where:
- = number of observed dimensions, = number of observations, = number of latent factors ()
- = loading matrix (relates latent factors to observations)
- = factor scores (latent representation)
- = diagonal noise covariance (FA); for PPCA
The fundamental assumption is that is low rank: most variance in is captured by a small number of latent directions.
Relation to PCA
| Model | Prior on | Noise |
|---|---|---|
| PCA (standard) | Deterministic | — |
| PPCA | (isotropic) | |
| Factor Analysis |
See also: Ghahramani & Roweis model diagram.
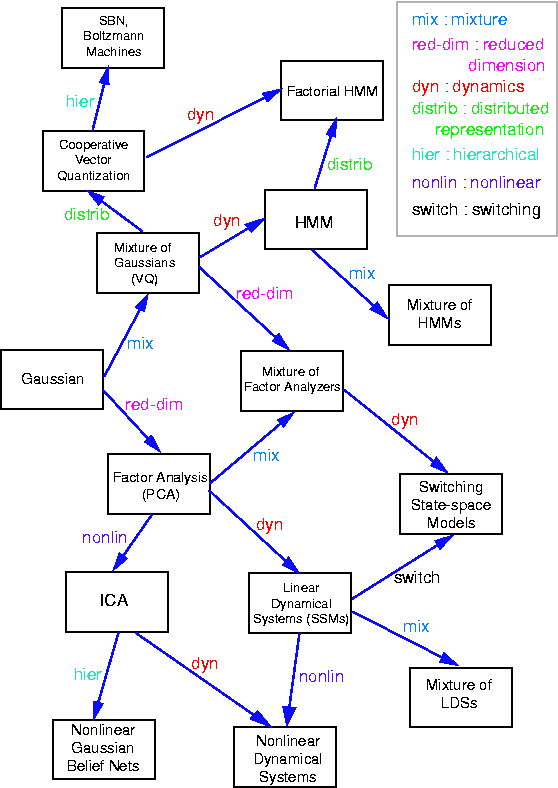{kind=link}
The Identifiability Problem
The naive model is non-identified: only the product enters the likelihood, so for any invertible . This causes factors and loadings to rotate, reflect, and permute freely between MCMC chains, producing:
- Inconsistent chain means (multi-modal posterior)
- Heavy autocorrelation in traceplots
Symptom
If and ESS is very low for entries, the model is not identified.
Constrained Parametrisation (Fix)
Restrict to be:
- Lower triangular — eliminates rotational freedom
- Positive, increasing diagonal entries — eliminates sign and permutation ambiguity (use cumulative sum of half-normal draws)
def makeW(d, k, dim_names):
n_od = int(k * d - k * (k - 1) / 2 - k)
z = pm.HalfNormal("W_z", 1.0, dims="latent_columns") # positive diag
b = pm.Normal("W_b", 0.0, 1.0, shape=(n_od,), dims="packed_dim") # off-diagonal
L = expand_packed_block_triangular(d, k, b, pt.ones(k))
W = pm.Deterministic("W", L @ pt.diag(pt.extra_ops.cumsum(z)), dims=dim_names)
return WWith this parametrisation, chains agree on posterior means and improves substantially.
Amortized Inference (Marginalizing Out )
Explicitly sampling the matrix is expensive for large and prevents minibatch streaming. Instead, integrate out analytically:
This reduces the parameter space to and only, enabling:
- Faster per-iteration computation (fewer parameters)
- Minibatch ADVI via
pm.Minibatch+pm.fit(method="fullrank_advi")
Tradeoff: Computing the log-prob requires inverting the covariance matrix, which is slow for large . MCMC on the amortized model is typically slower per sample but the reduced parameter count offsets this for large .
with pm.Model(coords=coords) as PPCA_amortized:
W = makeW(d, k, ("observed_columns", "latent_columns"))
sigma = pm.HalfNormal("sigma", 1.0)
cov = W @ W.T + sigma**2 * pt.eye(d)
X = pm.MvNormal("X", 0.0, cov=cov, observed=Y.T, dims=("rows", "observed_columns"))Post-hoc Recovery of Factor Scores
After fitting the amortized model (where was marginalized away), recover individual factor scores using the conjugate posterior:
This is amortized inference: we postpone computing individual until after model fitting, then recover them analytically from the posterior samples of and .
Reconstruction Quality
Model quality can be assessed by comparing the reconstruction against the original data. A scatter plot of observed vs. reconstructed values with from linear regression provides a quick diagnostic.
Scalability Summary
| Approach | Fits large ? | Minibatch? | Notes |
|---|---|---|---|
| Explicit (MCMC) | No — params | No | Simplest but slow |
| Amortized (MCMC) | Moderate | No | Covariance inversion bottleneck |
| Amortized (ADVI) | Yes | Yes | FullRankADVI + Minibatch |
See Also
- Nonparametric Models Overview — Gaussian processes as infinite-dimensional factor models
- Generalized Linear Models — Linear Gaussian models in the GLM framework
- Approximation Methods — ADVI and variational inference methods used here
- Factor analysis — Full PyMC tutorial with code and plots
- Vine Copulas - Overview — latent-structure vs pairwise dependence modeling