source
generate_grouped_data
generate_grouped_data (sample_size:int, n_exogenous_vars:int,
n_confounders:int=0, n_groups:int=1,
n_group_attributes:int=0, group_var:float=3,
noise_sigma:float=1,
random_effect_assumption_satified:bool=True,
random_seed:Optional[int]=None)
Generate grouped regression data
sample_size
int
Number of samples per group
n_exogenous_vars
int
Number of exogenous variables
n_confounders
int
0
Number of confounder variables
n_groups
int
1
Number of independent groups
n_group_attributes
int
0
Number of group level attributes
group_var
float
3
Variance between groups
noise_sigma
float
1
Std of noise for each observation
random_effect_assumption_satified
bool
True
Is random effect assumption valid
random_seed
Optional
None
Returns Dataset Synthetic dataset
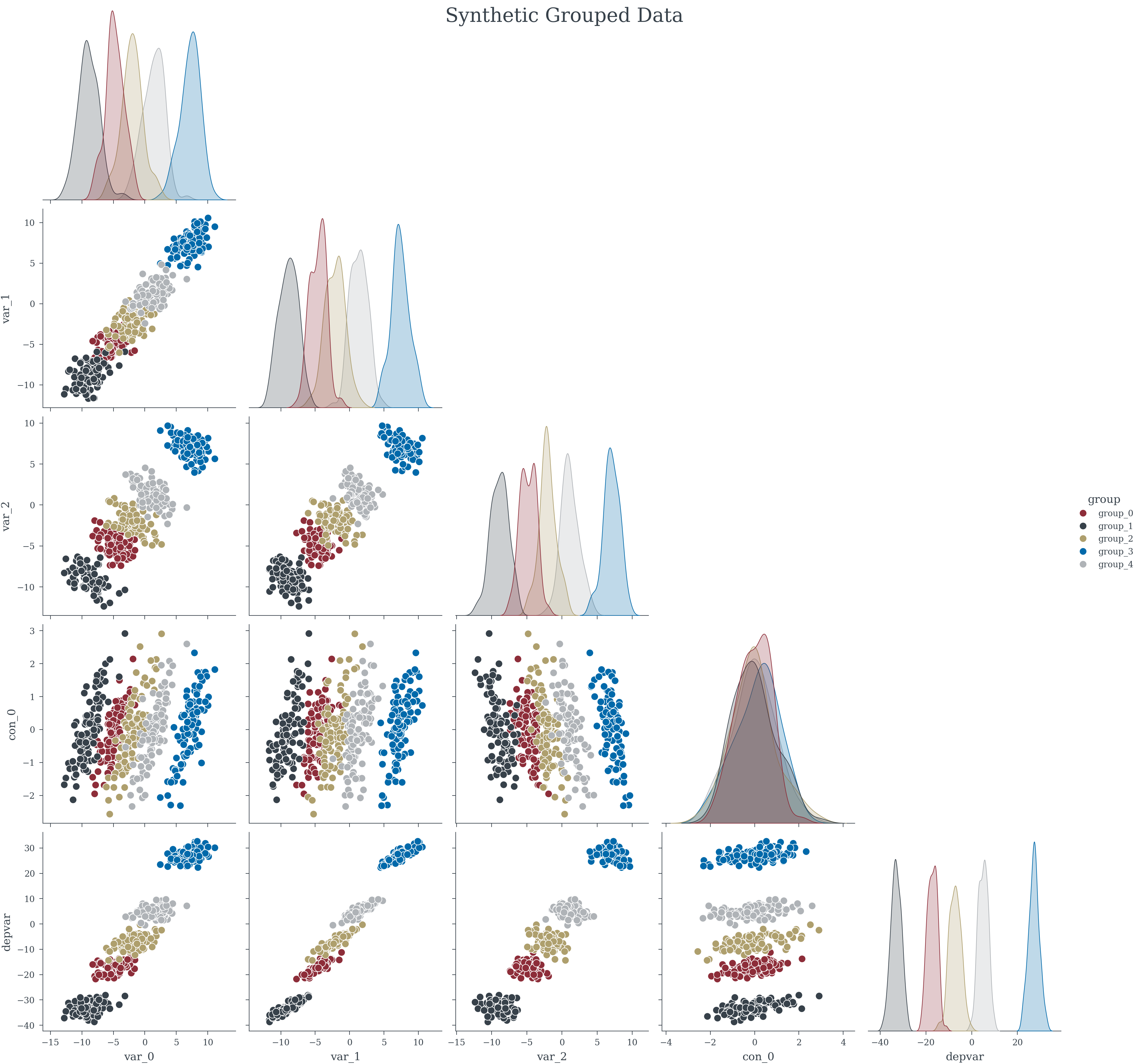
= generate_grouped_data(100 , 3 , = 1 , n_groups= 5 , = 42 , = False )
<xarray.Dataset> Size: 1kB
Dimensions: (group: 5, index: 5)
Coordinates:
* group (group) <U7 140B 'group_0' 'group_1' 'group_2' 'group_3' 'group_4'
* index (index) int64 40B 0 1 2 3 4
Data variables:
var_0 (group, index) float64 200B -4.29 -5.247 -3.251 ... 2.224 2.565
var_1 (group, index) float64 200B -6.002 -6.595 -4.969 ... 3.201 2.787
var_2 (group, index) float64 200B -6.836 -5.554 -4.949 ... 0.9918 1.975
con_0 (group, index) float64 200B 0.3047 -1.04 0.7505 ... -0.3937 0.5212
depvar (group, index) float64 200B -20.39 -19.84 -17.33 ... 6.005 7.054
Attributes:
true_alpha: [[ -9.12693519]\n [-17.69415699]\n [ -3.57316472]\n [ 14.463...
true_betas: {'var_0': -0.0102, 'var_1': 1.5902, 'var_2': 0.1593} Dimensions:
Coordinates: (2)
Data variables: (5)
var_0
(group, index)
float64
-4.29 -5.247 -3.251 ... 2.224 2.565
array([[ -4.28993336, -5.24701375, -3.25126756, -2.66829812, -7.96874031],
[ -8.87000995, -7.83520097, -10.5691001 , -7.08088071, -9.83225184],
[ -1.49435767, -0.23375686, -3.03502379, -2.62791234, -4.05308145],
[ 9.05369034, 4.48173864, 8.6913756 , 6.35172464, 7.36224679],
[ 0.45741539, 2.58032894, 3.60114386, 2.22384135, 2.56476205]]) var_1
(group, index)
float64
-6.002 -6.595 ... 3.201 2.787
array([[-6.00174201, -6.59544669, -4.96867735, -3.7252721 , -6.63981273],
[-9.37953311, -7.53548951, -9.04050391, -7.00667713, -9.99760142],
[-2.35404051, -3.3344299 , -3.23959722, -3.17685254, -6.02774525],
[ 9.15203236, 6.39415109, 9.81129207, 6.70474757, 7.5229281 ],
[ 2.42470019, 2.86860677, 1.20691427, 3.20135074, 2.78657969]]) var_2
(group, index)
float64
-6.836 -5.554 ... 0.9918 1.975
array([[ -6.83612943, -5.5535033 , -4.94906834, -6.01101911, -1.90366831],
[ -8.44989128, -10.41341108, -8.01211621, -6.4169537 , -9.90583764],
[ -2.29872482, -3.96801742, -1.88125553, -2.98965978, -0.99604602],
[ 5.95186917, 8.47554027, 6.11814611, 8.10250144, 8.17854086],
[ -1.46338471, 2.3732775 , -2.31343828, 0.99178827, 1.9749268 ]]) con_0
(group, index)
float64
0.3047 -1.04 ... -0.3937 0.5212
array([[ 0.30471708, -1.03998411, 0.7504512 , 0.94056472, -1.95103519],
[-0.37816255, 1.2992283 , -0.35626397, 0.73751557, -0.93361768],
[ 0.33757455, 1.40748186, 0.09058491, 0.64393879, -2.0501721 ],
[ 1.72735021, -1.5338614 , 0.86382801, -0.32852522, -0.06132435],
[-0.17961141, 0.1967761 , 0.82052848, -0.39374117, 0.52116726]]) depvar
(group, index)
float64
-20.39 -19.84 ... 6.005 7.054
array([[-20.38511533, -19.83524377, -17.32791668, -15.9930025 , -20.6428855 ],
[-33.74712208, -31.077567 , -32.45654011, -29.25188177, -34.99982213],
[ -7.77510303, -10.19414017, -10.48167343, -8.99991138, -13.98672133],
[ 30.22903947, 28.21302496, 30.65645951, 26.77967958, 28.91338538],
[ 5.62018538, 8.15337138, 1.79307287, 6.00522818, 7.05355403]]) Indexes: (2)
PandasIndex
PandasIndex(Index(['group_0', 'group_1', 'group_2', 'group_3', 'group_4'], dtype='object', name='group')) PandasIndex
PandasIndex(Index([0, 1, 2, 3, 4], dtype='int64', name='index')) Attributes: (2)
true_alpha : [[ -9.12693519]
[-17.69415699]
[ -3.57316472]
[ 14.4630254 ]
[ 2.62920112]] true_betas : {'var_0': -0.0102, 'var_1': 1.5902, 'var_2': 0.1593}
= data.to_dataframe().reset_index()= df.join(pd.get_dummies(df.group).astype(int ))
0
group_0
0
-4.289933
-6.001742
-6.836129
0.304717
-20.385115
1
0
0
0
0
1
group_0
1
-5.247014
-6.595447
-5.553503
-1.039984
-19.835244
1
0
0
0
0
2
group_0
2
-3.251268
-4.968677
-4.949068
0.750451
-17.327917
1
0
0
0
0
3
group_0
3
-2.668298
-3.725272
-6.011019
0.940565
-15.993002
1
0
0
0
0
4
group_0
4
-7.968740
-6.639813
-1.903668
-1.951035
-20.642885
1
0
0
0
0
= sm.OLS('depvar' ], 'group_0' , 'group_1' , 'group_2' , 'group_3' , 'group_4' , 'var_0' , 'var_1' , 'var_2' , 'con_0' = 'cluster' , = {'groups' : pd.factorize(df_with_dummies["group" ])[0 ]= True )
OLS Regression Results
Dep. Variable:
depvar
R-squared:
0.998
Model:
OLS
Adj. R-squared:
0.998
Method:
Least Squares
F-statistic:
nan
Date:
Sat, 09 Nov 2024
Prob (F-statistic):
nan
Time:
22:13:46
Log-Likelihood:
-714.05
No. Observations:
500
AIC:
1446.
Df Residuals:
491
BIC:
1484.
Df Model:
8
Covariance Type:
cluster
coef
std err
t
P>|t|
[0.025
0.975]
group_0
-8.6226
0.297
-29.009
0.000
-9.448
-7.797
group_1
-16.5405
0.535
-30.937
0.000
-18.025
-15.056
group_2
-3.3568
0.124
-27.174
0.000
-3.700
-3.014
group_3
13.6005
0.424
32.043
0.000
12.422
14.779
group_4
2.5296
0.066
38.340
0.000
2.346
2.713
var_0
0.0602
0.029
2.107
0.103
-0.019
0.140
var_1
1.5980
0.028
57.342
0.000
1.521
1.675
var_2
0.2006
0.063
3.200
0.033
0.027
0.375
con_0
-0.1632
0.079
-2.075
0.107
-0.382
0.055
Omnibus:
1.163
Durbin-Watson:
1.803
Prob(Omnibus):
0.559
Jarque-Bera (JB):
0.962
Skew:
-0.062
Prob(JB):
0.618
Kurtosis:
3.176
Cond. No.
221.
Notes:
[1] Standard Errors are robust to cluster correlation (cluster)
= sm.OLS('depvar' ], 'var_0' , 'var_1' , 'var_2' , 'con_0' ]])= True )
OLS Regression Results
Dep. Variable:
depvar
R-squared:
0.995
Model:
OLS
Adj. R-squared:
0.995
Method:
Least Squares
F-statistic:
2.412e+04
Date:
Sat, 09 Nov 2024
Prob (F-statistic):
0.00
Time:
22:13:47
Log-Likelihood:
-900.38
No. Observations:
500
AIC:
1811.
Df Residuals:
495
BIC:
1832.
Df Model:
4
Covariance Type:
nonrobust
coef
std err
t
P>|t|
[0.025
0.975]
const
0.1839
0.069
2.683
0.008
0.049
0.319
var_0
0.7034
0.053
13.397
0.000
0.600
0.807
var_1
2.1893
0.052
41.741
0.000
2.086
2.292
var_2
0.8212
0.053
15.420
0.000
0.717
0.926
con_0
-1.0991
0.120
-9.138
0.000
-1.335
-0.863
Omnibus:
7.551
Durbin-Watson:
1.857
Prob(Omnibus):
0.023
Jarque-Bera (JB):
8.085
Skew:
-0.222
Prob(JB):
0.0176
Kurtosis:
3.438
Cond. No.
19.9
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
= data - data.mean(dim= 'index' )= mean_adj.to_dataframe().reset_index()= (int )
0
group_0
0
0.481425
-1.406211
-2.004544
0.354987
-3.170462
1
0
0
0
0
1
group_0
1
-0.475656
-1.999916
-0.721918
-0.989714
-2.620590
1
0
0
0
0
2
group_0
2
1.520091
-0.373147
-0.117483
0.800721
-0.113263
1
0
0
0
0
3
group_0
3
2.103060
0.870259
-1.179433
0.990834
1.221651
1
0
0
0
0
4
group_0
4
-3.197382
-2.044282
2.927917
-1.900766
-3.428232
1
0
0
0
0
= sm.OLS('depvar' ], 'var_0' , 'var_1' , 'var_2' , 'con_0' ]])= True )
OLS Regression Results
Dep. Variable:
depvar
R-squared (uncentered):
0.795
Model:
OLS
Adj. R-squared (uncentered):
0.793
Method:
Least Squares
F-statistic:
481.0
Date:
Sat, 09 Nov 2024
Prob (F-statistic):
3.90e-169
Time:
22:13:52
Log-Likelihood:
-714.05
No. Observations:
500
AIC:
1436.
Df Residuals:
496
BIC:
1453.
Df Model:
4
Covariance Type:
nonrobust
coef
std err
t
P>|t|
[0.025
0.975]
var_0
0.0602
0.046
1.322
0.187
-0.029
0.150
var_1
1.5980
0.044
36.038
0.000
1.511
1.685
var_2
0.2006
0.045
4.421
0.000
0.111
0.290
con_0
-0.1632
0.092
-1.766
0.078
-0.345
0.018
Omnibus:
1.163
Durbin-Watson:
1.803
Prob(Omnibus):
0.559
Jarque-Bera (JB):
0.962
Skew:
-0.062
Prob(JB):
0.618
Kurtosis:
3.176
Cond. No.
4.73
Notes:
[1] R² is computed without centering (uncentered) since the model does not contain a constant.
[2] Standard Errors assume that the covariance matrix of the errors is correctly specified.
= sm.OLS('depvar' ], 'var_0' , 'var_1' , 'var_2' , 'con_0' ]])= 'cluster' , = {'groups' : df_demeaned_with_dummies['group' ]= True )
OLS Regression Results
Dep. Variable:
depvar
R-squared (uncentered):
0.795
Model:
OLS
Adj. R-squared (uncentered):
0.793
Method:
Least Squares
F-statistic:
3.833e+04
Date:
Sat, 09 Nov 2024
Prob (F-statistic):
2.04e-09
Time:
22:27:47
Log-Likelihood:
-714.05
No. Observations:
500
AIC:
1436.
Df Residuals:
496
BIC:
1453.
Df Model:
4
Covariance Type:
cluster
coef
std err
t
P>|t|
[0.025
0.975]
var_0
0.0602
0.028
2.118
0.102
-0.019
0.139
var_1
1.5980
0.028
57.633
0.000
1.521
1.675
var_2
0.2006
0.062
3.217
0.032
0.027
0.374
con_0
-0.1632
0.078
-2.085
0.105
-0.380
0.054
Omnibus:
1.163
Durbin-Watson:
1.803
Prob(Omnibus):
0.559
Jarque-Bera (JB):
0.962
Skew:
-0.062
Prob(JB):
0.618
Kurtosis:
3.176
Cond. No.
4.73
Notes:
[1] R² is computed without centering (uncentered) since the model does not contain a constant.
[2] Standard Errors are robust to cluster correlation (cluster)
= sm.OLS('depvar' ], 'group_0' , 'group_1' , 'group_2' , 'group_3' , 'group_4' ,'var_0' , 'var_1' , 'var_2' , 'con_0' ]])= 'cluster' , = {'groups' : df_demeaned_with_dummies['group' ]= True )
OLS Regression Results
Dep. Variable:
depvar
R-squared:
0.795
Model:
OLS
Adj. R-squared:
0.792
Method:
Least Squares
F-statistic:
nan
Date:
Sat, 09 Nov 2024
Prob (F-statistic):
nan
Time:
22:28:30
Log-Likelihood:
-714.05
No. Observations:
500
AIC:
1446.
Df Residuals:
491
BIC:
1484.
Df Model:
8
Covariance Type:
cluster
coef
std err
t
P>|t|
[0.025
0.975]
group_0
8.5920
0.297
28.907
0.000
7.767
9.417
group_1
16.5130
0.535
30.886
0.000
15.029
17.997
group_2
3.9143
0.124
31.687
0.000
3.571
4.257
group_3
-13.5953
0.424
-32.031
0.000
-14.774
-12.417
group_4
-2.4543
0.066
-37.198
0.000
-2.637
-2.271
var_0
0.0602
0.029
2.107
0.103
-0.019
0.140
var_1
1.5980
0.028
57.342
0.000
1.521
1.675
var_2
0.2006
0.063
3.200
0.033
0.027
0.375
con_0
-0.1632
0.079
-2.075
0.107
-0.382
0.055
Omnibus:
1.163
Durbin-Watson:
1.803
Prob(Omnibus):
0.559
Jarque-Bera (JB):
0.962
Skew:
-0.062
Prob(JB):
0.618
Kurtosis:
3.176
Cond. No.
221.
Notes:
[1] Standard Errors are robust to cluster correlation (cluster)
'depvar ~ var_0 + var_1 + var_2 + con_0' , = df_with_dummies, = df_with_dummies['group' ]= ["lbfgs" ]
Model:
MixedLM
Dependent Variable:
depvar
No. Observations:
500
Method:
REML
No. Groups:
5
Scale:
1.0373
Min. group size:
100
Log-Likelihood:
-745.7758
Max. group size:
100
Converged:
Yes
Mean group size:
100.0
Coef.
Std.Err.
z
P>|z|
[0.025
0.975]
Intercept
-2.458
5.051
-0.487
0.627
-12.358
7.443
var_0
0.065
0.046
1.419
0.156
-0.025
0.155
var_1
1.602
0.045
35.910
0.000
1.515
1.690
var_2
0.205
0.046
4.495
0.000
0.116
0.295
con_0
-0.170
0.093
-1.832
0.067
-0.352
0.012
Group Var
127.501
89.028